文章中涉及到的 Vue 代码特指版本 2.6.11。
虚拟 DOM
什么是虚拟 DOM
要理解 Diff 算法,就得先理解好虚拟 DOM。虚拟 DOM 说白了其实就只是一个 JavaScript 对象,它抽象地描述了一个真实的 DOM 结构。我们可以从 Chrome 的 DevTools 中看到,一个 DOM 结构无非是由很多个 HTML 标签根据父子、兄弟等关系组织起来的,而每个 HTML 标签又包含了各种属性,比如 style、class、src 等。所以只要知道了真实 DOM 的结构,我们就可以把它抽象成一个对象的形式来描述,这个对象就是虚拟 DOM。我们可以通过递归的方式将一个 DOM 结构解析成一个虚拟 DOM,也可以通过 document.createElement 把一个虚拟 DOM 还原成一个真实 DOM。
Vue 中一个虚拟 DOM 节点(VNode) 包含了很多项数据,具体可以看源码 vue/src/core/vdom/vnode.js。但为了方便,在这里一个 VNode 包含最基本的三个属性就可以了,分别是节点类型 tag、属性 data、子元素 children。
<div id="container" class="p-container">
<h1>Real DOM</h1>
<ul style="color: red">
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</div>
举个栗子,上面这个 DOM 结构,我们可以把它抽象成如下的一个虚拟 DOM 结构。不难发现,真实 DOM 和 虚拟 DOM 是可以相互转化的。
const VirtualDOM = {
tag: 'div',
data: {
id: 'container',
class: 'p-container'
},
children: [
{
tag: 'h1',
data: {},
children: ['Real DOM'],
},
{
tag: 'ul',
data: {
style: "color: red"
},
children: [
{
tag: 'li',
data: {},
children: ['Item1']
},
{
tag: 'li',
data: {},
children: ['Item2']
},
{
tag: 'li',
data: {},
children: ['Item3']
}
]
}
]
}
为什么要有虚拟 DOM
在以前还没有框架的时候,前端开发几乎都是靠原生 JavaScript 或者是 JQuery 一把梭进行 DOM 操作的。那么为什么 React 和 Vue 都采用了虚拟 DOM 呢?我理解的虚拟 DOM 的优势是:
跨平台渲染。借助虚拟 DOM 后 FrontEnd 可以进行移动端、小程序等开发。因为虚拟 DOM 本身只是一个 JavaScript 对象,所以可以先由 FE 们写 UI 并抽象成一个虚拟 DOM,再由安卓、IOS、小程序等原生实现根据虚拟 DOM 去渲染页面(React Native、Weex)。
函数式的 UI 编程。将 UI 抽象成对象的形式,相当于可以以编写 JavaScript 的形式来写 UI。
网上 Blog 常常会说到虚拟 DOM 会有更好的性能,因为虚拟 DOM 只会在 Diff 后修改一次真实 DOM,所以不会有大量的重排重绘消耗。并且只更新有变动的部分节点,而非更新整个视图。但我对这句话是存疑的,通过下文的 Diff 算法源码可以发现,Vue2 它的 Diff 是每次比对到匹配到的节点后就去修改真实 DOM 的,并不是等所有 Diff 完后再修改一次真实 DOM 而已。
虚拟 DOM 一定会更快吗
我的理解是不一定。如果一个页面的整个 DOM 结构都改变了的话,使用虚拟 DOM 不仅一样要绘制渲染整个视图,而且还要进行 Diff 算法,会比直接操作真实 DOM 更慢,所以虚拟 DOM 带来的性能优势并不是绝对的。
而且不管框架如何封装、掩盖底层操作,终究是需要去调用到 DOM 相关的 api 更新页面的。并且它可能还包含了其他一些 Diff、polyfill、封装逻辑等,这样是不会比我们直接进行 DOM 操作更新 UI 快的。只是,难道我们每修改数据,就要手动操作 DOM 吗?虽然这样会更快,但带来的是很差的代码可读性和可维护性,这样得不偿失。所以正如尤雨溪说的,这是一个性能 VS 可维护性的取舍问题。
推荐阅读:
网上都说操作真实 DOM 慢,但测试结果却比 React 更快,为什么?
Diff 算法
什么是 Diff 算法
首先我们先了解一下使用了虚拟 DOM 后的渲染流程:
将真实 DOM 抽象成虚拟 DOM。
数据改变时,将新的真实 DOM 再抽象成另一个新的虚拟 DOM。
采用深度优先遍历新旧两个虚拟 DOM,如果两个虚拟 DOM 节点值得比较,就递归比较它们的子节点,否则直接创建新的 DOM 节点。
template/JSX -> Render Function -> Vnode(做 Diff)-> DOM
可以看到,所谓的 Diff 算法,其实就是上述第三个步骤中比对两个虚拟 DOM 所使用的算法。Diff 算法的优劣直接决定了页面性能的好坏,有的 Diff 算法时间复杂度是 O(n^3),有的 Diff 算法时间复杂度是 O(n)。关于时间复杂度的问题,下文再分析。
Vue2 中 Diff 原理
相关源码参考 vue/src/core/vdom/patch.js
我们先通过图文来看 Vue 中的 Diff 流程,等理解了之后再来看源码,不然直接看源码的话容易懵 Orz。
当对新旧两个虚拟 DOM 做 Diff 时,Vue 采用的思想是同级比较、深度递归、双端遍历。
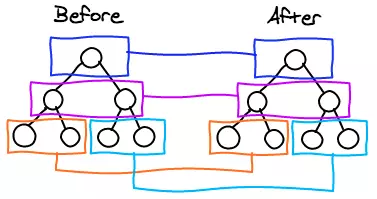
同级比较
同级比较指的是只比对两个相同层级的 VNode,如果两者不一样了,就不再去 Diff 它们的子节点,更不会去跨层级比较,而是直接更新它。这是因为在我们平时的操作,很少出现将一个 DOM 节点进行跨层级移动,比如将原来的父节点移动到它子节点的位置上。所以 Diff 算法就没有为这个极少数的情况专门去跨层级 Diff,毕竟为此得不偿失,这也是 Diff 算法时间复杂度能从 O(n^3) 优化到 O(n) 的原因之一。
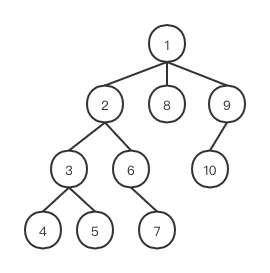
深度递归
深度递归指的是比较两个虚拟 DOM 时采用深度优先的先序遍历策略,先比较完一个子节点后,就去比较这个子节点的子孙节点,都递归完后再来遍历它的兄弟节点。如下图的一个 DOM 结构,节点的编号就是它们的遍历顺序。
那么为什么要使用深度优先遍历,广度优先遍历不行么?我的理解是,深度优先遍历使用到的是栈结构,进行深度递归的时候,栈中保存的是当前节点的父元素和祖先元素,栈中存储的最大节点个数就是 DOM 树最大的层级数。而广度优先遍历使用的是队列结构,进行广度递归的时候,队列中保存的是下一层的节点,队列中存储的最大节点个数就是 DOM 树最大的层级节点数。而在通常情况下,一个 DOM 树的层级数是会少于它的层级节点数的(比如一个列表信息组件),所以使用深度优先遍历占用的空间和消耗会更小些。
双端比较
双端比较指的是在 Diff 新旧子节点时,使用了四个指针分为四种比较方法(当然还有最后一种通过 key 比较的,这个待会再说)。这四个指针分别是:
oldStartIdx表示旧 VNode 从左边开始 Diff 的节点,初始值为第一个子节点oldEndIdx表示旧 VNode 从右边开始 Diff 的节点,初始值为最后一个子节点newStartIdx表示新 VNode 从左边开始 Diff 的节点,初始值为第一个子节点newEndIdx表示新 VNode 从右边开始 Diff 的节点,初始值为最后一个子节点
对应的五种比较方法是:
oldStartIdx和newStartIdx首首比较。如果两者值得比较的话(值得比较的定义见下文源码解释部分,这里先理清 Diff 的比较过程),就递归比较它们的子节点,然后将两个指针右移。oldEndIdx和newEndIdx尾尾比较。如果两者值得比较的话,就递归比较它们的子节点,然后将两个指针左移。oldStartIdx和newEndIdx首尾比较。如果两者值得比较的话,就递归比较它们的子节点,然后oldStartIdx指针右移,newEndIdx指针左移。oldEndIdx和newStartIdx尾首比较。如果两者值得比较的话,就递归比较它们的子节点,然后oldEndIdx指针左移,newStartIdx指针右移。如果这四种方法都没能匹配到对应的 VNode,就会通过 key 来比较。先找到
newStartIdx的 key 在旧虚拟 DOM 里对应的位置,找得到的话则判断两者是否值得比较,值得则递归比较它们的子节点,不值得或是找不到的话就直接创建新节点,并将newStartIdx右移。
对于新旧子节点,只要旧子节点或是新子节点遍历完了,就会退出上述的比较过程。而剩下的子节点,已经没有能和它们比对的 VNode 了,要么是新增要么是删除。
图文模拟 Diff 流程
现在我们用个栗子来模拟下这个过程 。如下图所示的新旧虚拟 DOM,假设旧 VNode 有 a、b、d、e 四个子节点,页面经过某次更新后,新 VNode 的子节点是 a、c、d、b。要说明的是,图中的节点编号为它们各自的 key,并且排列的顺序是按照它们在真实 DOM 中的顺序来的。
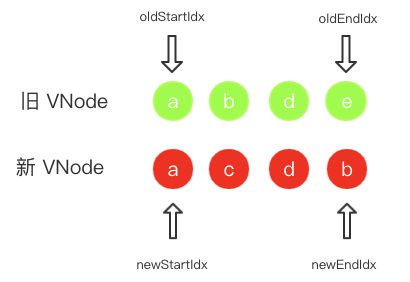
DOM 节点的变化无外乎是改变文本、改变节点属性、节点增删移动这几种情况。我们可以先通过上图来推测这次页面更新对该节点的操作:对 a 和 d 节点不做任何改动或是修改了文本或属性,移动了 b、删除了 e、新增了 c。详细比较过程如下:
- 首首比较 a 和 a,发现两者值得比较后递归比较子节点,并移动两个指针后状态如下。
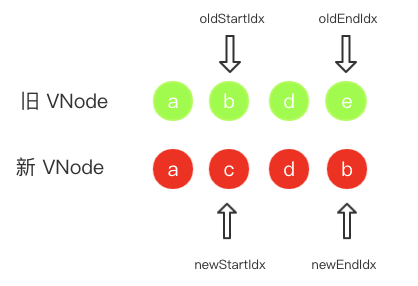
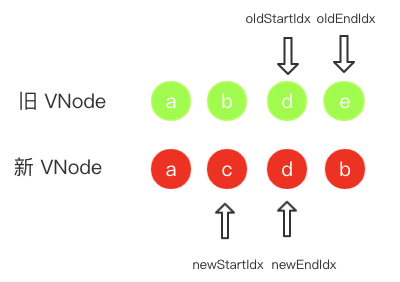
- 首首比较 b 和 c 两者不匹配,接着尾尾比较 e 和 b 还是不匹配,再首尾比较 b 和 b 匹配上了,于是递归它们的子节点并移动两个指针后。由于新旧 VNode 上节点的位置发生了变化,所以需要在真实 DOM 上移动节点 b,即把它插入到
oldEndIdx的位置上。现在的状态图如下(因为是移动真实 DOM 节点,所以虚拟 DOM 上节点的顺序还是不会改变)。
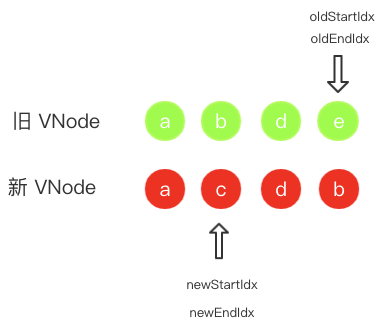
- 首首比较 d 和 c 两者不匹配,再尾尾比较 e 和 d 还是不匹配,再首尾比较 d 和 d 匹配上了,还是照常递归子节点并移动指针位置。现在的状态图如下。
- 首首比较 e 和 c、尾尾比较 e 和 c、首尾比较 e 和 c、尾首比较 e 和 c,两者都不匹配,于是进入到查找 key 的环节。这里查找 key 有两种方法,一是以旧子节点的 key 为键,它的索引下标为值建立一个映射对象,在该映射对象里直接查找是否存在
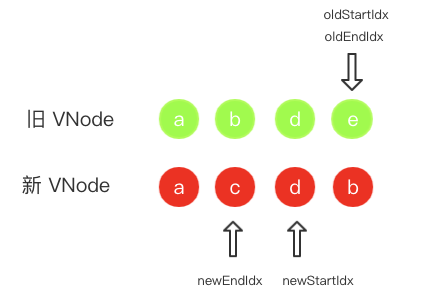
newStartIdx也就是 c 节点的 key。找不到的话就再用第二种方法,即遍历旧子节点列表,去一个个判断 key 是和 c 节点的 key 相等。如果通过这两种方法能找到相等的 key 节点的话,则判断两者是否值得比较,是的话就递归比较两者的子节点并在真实 DOM 中移动节点。而在这个栗子中上述两种方法都没能在旧子节点列表里找到 key 为 c 的节点,于是创建节点 c 并插入到newStartIdx的位置上。因为在旧 VNode 中没有找到匹配的节点,所以旧 VNode 的指针不需要移动,只需要右移新 VNode 的指针。指针移动后现在的状态图如下。
- 可以看到,在新 VNode 中
newStartIdx已经大于newEndIdx,也就是已经遍历完新 VNode 了。只要新 VNode 或是旧 VNode 遍历完了,就不能再比对新旧 VNode 了,而是要进行删除或增加操作。- 如果是旧 VNode 先遍历完,也就意味着新 VNode 中还有几个节点没有在旧 VNode 中匹配到,说明这几个节点是新增加的。这时候需要将
newStartIdx至newEndIdx之间的节点都创建出新节点,并插入到相应的位置上。 - 如果是新 VNode 先遍历完,也就意味着旧 VNode 中还有几个节点没有在新 VNode 中匹配到,说明这几个节点是被删除了的,这时候需要在真实 DOM 中移除掉
oldStartIdx至oldEndIdx之间的节点。比如本栗子,就需要移除掉节点 e。
- 如果是旧 VNode 先遍历完,也就意味着新 VNode 中还有几个节点没有在旧 VNode 中匹配到,说明这几个节点是新增加的。这时候需要将
OK,Diff 的流程到这里就结束了。读者可以再理一遍这个双端比较的过程,看完之后看看能不能发现什么疑惑点。我看的时候有以下几个疑惑点:
疑惑一:双端比较中为什么要尾尾比较?
我的理解是,尾尾比较是为了加速比对时的命中率,提高 Diff 效率。比如现在有旧子节点列表 a b c,新子节点列表 b a c(偷个懒,这里就不画图啦)。如果没有尾尾比较的话,那它的第一次 Diff 比较顺序是:a 和 b、a 和 c、c 和 b、通过 key 比较。可以看到,这第一次 Diff 得通过 key 才能找到两个匹配的 VNode。而有尾尾比较的话,第一次 Diff 的比较顺序就变成了:a 和 b、c 和 c,至此就可以找到匹配的节点了,包括之后的两次 Diff 都不需要通过 key 比较。所以通过尾尾比较是可以提高 Diff 命中率的。
疑惑二:双端比较中为什么要首尾比较和尾首比较?
我的理解是,首尾比较和尾首比较同样是为了提高 Diff 效率。比如现在有旧子节点列表 a b c,新子节点列表 b c a,在这里的更新操作只是把 a 节点移动到了尾部,其他的 b 和 c 节点都没有变动。如果没有首尾比较的话,它的 Diff 比较顺序是:a 和 b、c 和 a、c 和 b、通过 key 比较。还是一样得通过 key 比较才能匹配到,而且之后还需要两次 Diff 并且依旧是通过 key 才能完成本次更新的 Diff 过程。如果有首尾比较的话,它的比较顺序就成了 a 和 b、c 和 a、a 和 a,匹配上后移动指针,发现剩下的 b c 节点都是相同的,都不需要再有多余的比对操作了。这样是不是大大提高了 Diff 的效率?尾首比较也是同理。
疑惑三:使用 Vue 时我们常常会给节点赋予一个独一无二的 key,通过双端比较的过程能不能明白这是为什么?
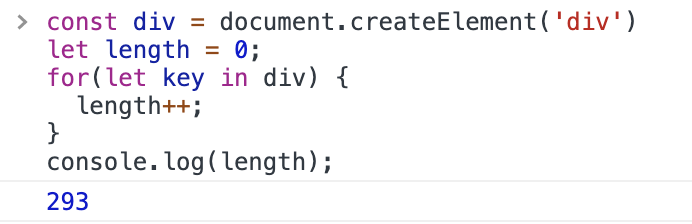
我的理解是,如果我们编码时没有给节点一个 key 的话,它在上述五种比较方法都匹配不到后就会直接创建新的真实 DOM 节点并插入到相应位置。而创建一个真实 DOM 节点其实消耗是挺大的,看下图可以发现,我们创建一个 div 节点,它的初始属性都有 293 个。所以在能复用原 DOM 节点的时候就应该尽量复用,而不是重新创建。
Diff 过程的几种比较方法中,最好的是首首/尾尾/首尾/尾首比较,其次是通过 key 比较。那么为啥说首首比较这四种方法要优于通过 key 比较呢?不要忘了,通过 key 比较,不管是通过对象直接找到对应的 key,还是通过遍历一个个去找,它们都得先遍历一边旧子节点列表(第二种方法可能还不止遍历一次),而且通过对象直接找还得花费 O(n) 的空间复杂度。所以综合起来通过首首比较这四种方法进行比对,还是要优于通过 key 比对的。
我们先通过上述图文的形式理解 Diff 流程(也就是那十二个字,同级比较、深度递归、双端比较),并且也明白其中的几个疑惑点后,下面再来看具体源码就很容易理解了~
如何调试 Vue 源码
看源码的时候,我们最好能够边看源码理清它的逻辑,边 debugger 源码验证我们的理解是否正确,所以这里先介绍下如何在 VScode 中调试 Vue 源码。
clone 好 Vue 源码后,先 npm install 安装各项依赖,再 npm run dev 使用 rollup.js 对整个源码进行打包,在 package.json 中对应的命令行是:
"dev": "rollup -w -c scripts/config.js --environment TARGET:web-full-dev"
这里将环境变量设置为 web-full-dev,对应到 vue/scripts/config.js 中的配置是:
const builds = {
...,
'web-full-dev': {
entry: resolve('web/entry-runtime-with-compiler.js'),
dest: resolve('dist/vue.js'),
format: 'umd',
env: 'development',
alias: { he: './entity-decoder' },
banner
},
...
}
可以看到,它打包后的输出路径是 vue/dist/vue.js,并且通过终端提示可以知道,每当我们修改源码时它都会实时地重新打包并更新 dist/vue.js。所以我们可以在一个 HTML 文件中引入 dist/vue.js,接着在源码中打 debugger 和 console.log,通过浏览器访问该 HTML 页面就可以看到相应的断点和日志信息,以此我们就能知道 Vue 整个的执行流程啦~。
在调试源码的时候还可以开启 sourcemap,具体方法可以参考vue源码分析系列:用sourcemap调试源码。
Vue2 Diff 源码分析
现在我们来看 Vue 中和 Diff 相关的源码。为了方便阅读,以下摘抄的源码只截取其中重点的部分,只截取其中重点的部分,只截取其中重点的部分。
当初始化渲染、组件更新的时候,Vue 会调用原型上的 _update 函数进行 Diff。可以看到,其中主要是通过 vm.__patch__ 函数进行 Diff、获取修改补丁、更新 DOM 并返回新的真实 DOM 等操作。当页面初始化渲染时,此时 vm._vnode 为初始值 null,所以此时的更新操作走 vm.__patch__(vm.$el, vnode, hydrating, false)。
可以看到,两者的差别主要在于传递给 vm.__patch__ 函数的第一个参数不同。初始渲染时由于还没有保留虚拟 DOM,所以第一个参数是 vm.$el,即 Vue 实例使用的根 DOM 元素比如我们常用的 #app,它是一个真实的 DOM 节点。而之后更新页面时 prevVnode 都指向了上次更新后的虚拟 DOM,它是一个虚拟 DOM。在 vm.__patch__ 函数中它会判断第一个参数是真实的 DOM 节点还是虚拟 DOM,如果是真实的 DOM 节点的话就不进行 Diff,直接创建 DOM(相关代码下文会指出)。
至于传递的其他两个参数,hydrating 是用于服务端渲染时判断的,false 是一个特殊的标记只用于 <transition-group>,这两者和 Diff 没关系,暂时就不讨论了。
// vue/src/core/instance/lifecycle.js
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this
const prevVnode = vm._vnode
vm._vnode = vnode
if (!prevVnode) {
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */)
} else {
vm.$el = vm.__patch__(prevVnode, vnode)
}
接着我们继续看 vm.__patch__ 这个函数的定义。在 Web 和在 Weex 上 vm.__patch__ 的定义是不一样的,这里我们只看在 Web 上的。
// vue/src/platforms/web/runtime/index.js
import { patch } from './patch'
Vue.prototype.__patch__ = inBrowser ? patch : noop // noop 是一个空函数
// vue/src/platforms/web/runtime/patch.js
import { createPatchFunction } from 'core/vdom/patch'
export const patch: Function = createPatchFunction()
// vue/src/core/vdom/patch.js
export function createPatchFunction() {
return function patch (oldVnode, vnode, hydrating, removeOnly) {
...
}
}
oldVnode 表示旧的虚拟 DOM,vnode 表示新的虚拟 DOM。
可以发现,经过一层层调用,最后 Diff 和页面更新的操作是在这个 patch 函数里完成的。现在我们重点来看 patch 的源码。
function patch (oldVnode, vnode) {
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode)
} else {
if (isRealElement) {
oldVnode = emptyNodeAt(oldVnode)
}
createElm(vnode)
removeVnodes(oldVnode)
}
return vnode.elm
}
其中,isDef 函数用于判断当前参数是否等于 undefined 或者 null,都不等于时 isDef 才返回 true。
首先它会通过 isRealElement 判断旧的虚拟 DOM 即 oldVnode 是不是一个真实的 DOM 节点(页面第一次渲染时 oldVnode 为真实 DOM 节点,之后更新页面时 oldVnode 才为虚拟 DOM),只有 oldVnode 为虚拟 DOM 并且新旧两个虚拟 DOM 值得比较时,才会调用 patchVnode 函数进行 Diff 和更新。否则就直接根据新的虚拟 DOM 创建真实 DOM 并插入到页面,并移除掉旧的虚拟 DOM(如果 oldVnode 为真实 DOM 的话,还需要先调用 emptyNodeAt 创建虚拟 DOM)。
理清了页面第一次渲染和页面更新的不同操作后,现在来看看上文的一个疑惑点,什么叫做只有新旧两个虚拟 DOM 值得比较时才会进行 Diff?如何判断两个 VNode 是否值得比较呢?判断的依据主要是三点:key、tag 和 data。key 和 tag 比较容易理解,如果节点的 key 和标签类型都变了,那自然就不用去 Diff 比较子节点变化,需要直接重新创建节点了。至于节点属性 data,我的理解是,比如一个 Button 按钮,它的 disabled 值改变了的话,这个节点实质上还是同一个,可以复用。而如果两个 VNode 一个有 data 一个没有的话,说明它们不是同一个节点,就需要重新创建了。
除此之外,如果节点是 input 输入框的话,还需要它的 type 相同才行,这是为了修复 5266 这个 bug,详情可以看 Github 原贴。
function sameVnode (a, b) {
return (
a.key === b.key &&
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
)
}
如果新旧两个 VNode 值得比较的话,就会执行 patchVnode 开始比较两个 VNode。
function patchVnode(oldVnode, vnode) {
if (oldVnode === vnode) {
return
}
const elm = vnode.elm = oldVnode.elm
const oldCh = oldVnode.children
const ch = vnode.children
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) {
updateChildren(elm, oldCh, ch)
}
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) {
setTextContent(elm, '')
}
addVnodes(elm)
} else if (isDef(oldCh)) {
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
setTextContent(elm, vnode.text)
}
}
vnode 表示新的虚拟 DOM 节点。
oldVnode 表示旧的虚拟 DOM 节点。
ch 表示 vnode 的子节点。
oldCh 表示 oldVnode 的子节点。
isUndef 函数判断参数是否为 undefined 或 null,是的话则返回 true。
patchVnode 进行的操作是,先判断新旧两个 VNode 是否一样,如果是同一个的话,则说明它没有变化可以直接结束比较了。如果两者不相等的话,则分为以下几种情况讨论:
vnode 和 oldVnode 相等,说明两者没有变化不用 Diff,可以直接退出 Diff 流程了。
vnode 是文本节点时,那么 oldVnode 也是文本节点,若两者的文本内容不相等,则修改节点的文本(如果一个 VNode 的
text属性不为undefined的话,就说明它是文本节点)。vnode 不是文本节点时,进一步判断 vnode 和 oldVnode 的子节点情况:
vnode 和 oldVnode 的子节点都存在且不相等,调用
updateChildren开始 Diff 算法比较子节点的差异。vnode 的子节点存在而 oldVnode 的不存在,说明此时的节点操作是新增,直接创建 vnode 的子节点并插入页面。
oldVnode 的子节点存在而 vnode 的不存在,说明此时的节点操作是删除,直接删除 vnode 的子节点。
如果 vnode 和 oldVnode 都没有子节点,并且 oldVnode 是文本节点的话,则将 oldVnode 的文本内容置为空。
这几个都比较容易理解,现在我们正式进入 Diff 的环节,也就是 updateChildren 函数。
function updateChildren (parentElm, oldCh, newCh) {
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
insertBefore(parentElm, oldStartVnode.elm, nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
createElm(newStartVnode)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode)
oldCh[idxInOld] = undefined
insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
createElm(newStartVnode)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
addVnodes(parentElm, newStartIdx, newEndIdx)
} else if (newStartIdx > newEndIdx) {
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
}
如上文图文解说双端比较的流程部分,只要理解了过程再看 updateChildren 函数就没什么难度了。这里也不再多解释这段源码,就只说说通过 key 比较的部分,里面涉及到了几个新函数。如上文说通过 key 比较有两种方法,一是建立 key 和索引下标的映射对象,二是遍历旧子节点一个个比较 key 是否相等。第一方法对应的是 createKeyToOldIdx 函数,如果在映射对象里找不到的话再去遍历,也就是 findIdxInOld 函数。
function createKeyToOldIdx (children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) {
map[key] = i
}
}
return map
}
function findIdxInOld (node, oldCh, start, end) {
for (let i = start; i < end; i++) {
const c = oldCh[i]
if (isDef(c) && sameVnode(node, c)) {
return i
}
}
}
需要注意的是 oldCh[idxInOld] = undefined 这个操作,如果在旧子节点中找到有和 newStartVnode 的 key 相等的旧子节点,还需要把这个 VNode 置为 undefined。这是因为通过 key 比较后旧 VNode 的指针并没有移动,这个旧 VNode 如果和 newStartVnode 匹配后没有置为 undefined,那么在后续的比对过程中可能和其他的新 VNode 匹配上。所以为了避免影响到后续的 Diff 操作,需要将它赋值为 undefined 表示这个节点已经匹配过了。
时间复杂度分析
我们常听到 React 和 Vue 的 Diff 算法时间复杂度从 O(n^3) 优化到了 O(n),n 是 DOM 中节点的个数。那么这个 O(n^3) 和 O(n) 是怎么来的呢?
我的理解是,在原来的 Diff 算法中,它并没有使用同层比较这个策略,而是将旧虚拟 DOM 的每个节点和新虚拟 DOM 的每个节点进行两两比较,这就已经有 O(n^2) 了。而找到匹配的两个节点后,又要通过移动等操作去改变真实 DOM,所以又有 O(n) 的消耗,所以总共就是 O(n^3)。
而优化后的 Diff 算法,因为使用了同层比较和双端比较,所以只需要比较同层级的节点就行,并且借助首尾四个指针可以直接将节点移动、删除到指定位置上,所以就只要 O(n) 的时间复杂度了。
Vue 和 React Diff 算法的不同点
这一块因为我还没有深入去研究 React 的 Diff 算法,只能暂且根据在网上 Blog 看到的做一下记录。
不同点:
Vue 是边比对 DOM 边更新,而 React 在比对时则保存更新点得到一个 patch 树,之后再统一批量更新 DOM。
Vue 的列表比对,采用从两端到中间的比对方式,而 React 则采用从左到右依次比对的方式。当一个集合只是把最后一个节点移动到了第一个,React 会把前面的节点依次移动,而 Vue 只会把最后一个节点移动到第一个。
结语
至此,Vue Diff 算法的流程和相关源码都解释完了。通过把自己的理解整理并输出为一篇 Blog,也算是加深了自己的理解吧~ BTW,面试真的很喜欢问 Diff 算法啊,这几天腾讯面试,一面二面都问到了 Diff 算法。哈哈,刚好这几天都在看 Diff 算法并边整理成了 Blog,面试的时候就将这篇 Blog 写到的几个主要点说了下。理解和写 Blog 花了好几天的时间,面试问答到 Diff 算法也就那么五分钟,这可以算是养兵千日,用兵一时么?
2020.5.18 补充,忽然想到一个问题。Vue 双向数据绑定通过数据劫持的方式,已经可以精确知道是哪个数据发生变化,发生了什么变化,那么为什么还要对虚拟 DOM 进行 Diff 差异呢?我自己没想到答案,网上一些 Blog 给出的解释是:
双向数据绑定绑定一个数据就需要一个 Watcher,一但我们的绑定细粒度过高就会产生大量的 Watcher,这会带来内存以及依赖追踪的开销,而细粒度过低会无法精准侦测变化。因此 Vue 的设计是选择中等细粒度的方案,在组件级别进行数据劫持侦测立即获取到变化的组件,而在组件内部进行虚拟 Dom Diff 比对差异。

